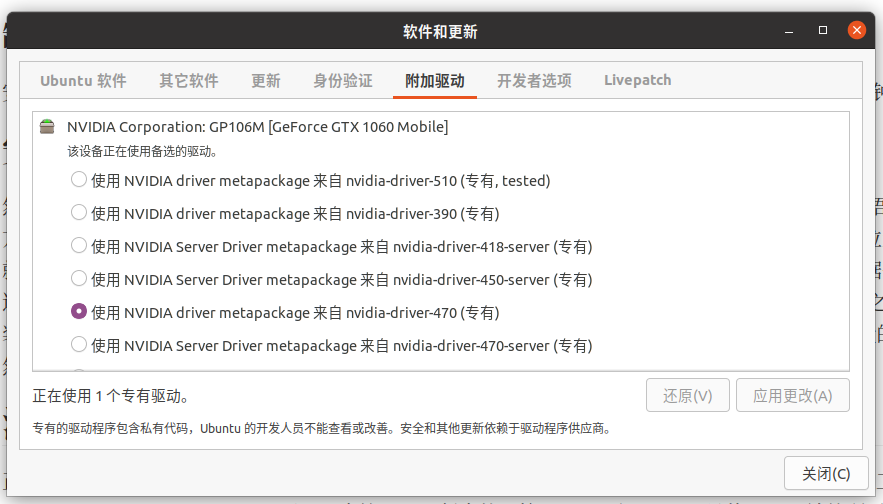
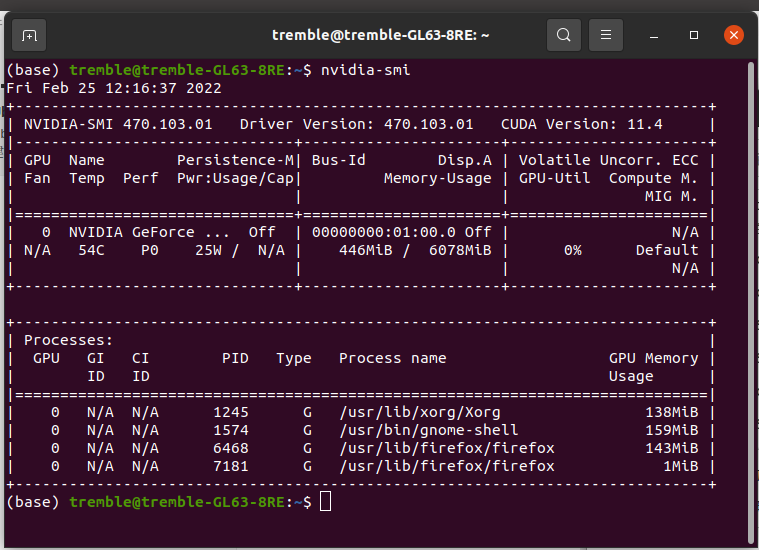
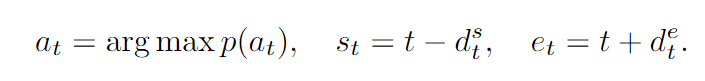这次秋招前期一直0offer,直到11月多才逐渐有差不多几家,最后开出来了一些,最终还是决定去钱多的地方,毕竟现在工作都不稳,钱多才是王道。
面试前的内容
算法 vs 开发
对于算法和开发的选择,我还是选择了算法,他们都说算法要有顶会,但是其实这个因素影响没有那么大的,我觉得不一定需要顶会,但是论文还是要有的,毕竟算法岗。没有顶会的情况下最重要的就是实习了,实习一定要把握住,这个可比顶会好拿到多了。我看往前几届的师兄师姐都去的开发岗,基本都是Java,但是这块我又不擅长,突击几个月还不一定有本科生学的好,干脆all in 算法了。毕竟算法还是比开发高很多的,还是可以冲下的。
另外一个选择的区别就是个人选择和未来规划,如果本科双非,同时没有科研论文,还没有实习,而且不打算后面卷,而是打算过几年回老家附近的地方,或者直接一步到位去二线城市,肯定直接Java,毕竟选择面非常广,Java的岗位数量遥遥领先,而且去国企银行运营商都好找工作。
如果还更有些追求,打算去大厂干几年,算法还是更好的,只是本科双非其实不算主要的问题,前提是有比较好的论文或者顶会,再想办法弄个实习,这样基本还是能找的,但要是都没有,那就不太容易了。
对于算法的准备,主要从以下几个方面展开,大致有力扣,简历,实习,秋招等。
力扣
力扣这是最基本的准备,毕竟除了人才计划,其他无论算法开发岗位都有力扣的考察,所以这个是一定要准备的。力扣的内容基本刷几遍hot100就差不多了,基本面试的手撕都是hot100这个难度,基本从前一年的12月就可以开始每天一道题了,开始的时候会很慢,后面慢慢熟练了就快了。之所以要开始这么早是因为实习是第二年三月就开始了,提前三个月准备刷题还是有必要的。很多人刷300题,基本肯定是够用了,有的人甚至刷了600题,其实不是特别有必要,力扣题主要起到的是一个门槛的作用,笔试不过直接pass,过的情况下主要看面试了。
简历
简历是非常重要的,决定了简历筛选后面能不能进笔试和面试,我简历凑合吧,投了90家,进面大概30家,正常水平吧。简历一般是先教育经历,之后最好是要有实习经历,然后是论文和科研部分,后面是项目可以放几个,后面是比赛获奖那些,主体就这些吧,具体根据不同人,优势不同,做的好的放前面一些。根据篇幅,后面可以加一些个人技能,比如编程语言和计算机工具比如Git、Linux什么的掌握情况,最后篇幅不够可以放自我评价,这个不是必须,可有可无。
对于简历的排版来说,也可直接按照不同模块的顺序,也有按照一个一个项目,然后每个项目后面跟着其中的产出论文成果以及技术栈,不同的都是可以的,根据自己实际情况来,总之自己最突出的地方要尽可能的放到比较显眼的前面。
对于简历是一页还是两页,我看不同HR喜好并不同,有的认为一页简单明了,有的觉得一页太单薄。总之校招一般不超过两页(博士除外),实际来看如果确实有内容建议充实两页,排版不要过于空旷,适当紧凑一些。
面试内容
一般一面或者二面技术面,自我介绍之后,如果有比较有含金量的实习或者论文会先讲这部分,之后会问项目之类的,之后有的会问一些八股,这个八股有的是算法八股比如Transformer、CNN、RNN卷积等什么的,这块需要背下。有的会问到计算机基础比如进程线程还有Python基础比如装饰器,线程锁啥的,这块只是有时候会问到。
然后就是面试中的手撕了,这个不是必须,有的面试会有手撕,这个因岗位和公司不同,手撕大部分是力扣,当然也有例外,比如淘天,投实习的时候手撕是手写多头注意力,交叉熵等题目,还有k-means的,这个不提前准备的话想快速写出来也不太容易。比如华子正式面试二面就出了个数字图像处理的手撕,很难,就蚌埠住了,这种题不多见。
技术面之后一般主管面,这块可能的问题很多,从个人信息到家里情况,到抗压测试,了解新信息的途径,其他还有比如人工智能对各行各业的影响,大模型在不同行业的应用,甚至包括盈利模式啥的等产品问题,不同的侧重点也不同,需要随机应变。这个部分不可小视,相关问题要整理下,大致想想如何回答。有的公司比如华子是技术面了可以捞,但是主管面挂了就不行。
实习
实习的重要程度可以说是第一了,毕竟一般如果组内条件不具备的话,是发不出来顶会的,尤其对于硕士,所以实习就成为了性价比最高而且最可以获取到的了。
准备实习第一步是要提前刷力扣题,然后准备简历润色,之后到三月下实习基本就开始了,四五月是最主要的时间,六月基本就不多了,建议尽早投递,一般越早越容易拿到Offer,前期看哪些先开,最开始的可以不投特别大的厂,因为没有相关经验,如果面的很差的话确实会影响面评,影响后面,不过大部分好像影响不大的,可以先从小厂开始,虽然很多时候大厂先开。在面试的过程中不断复盘,总结经验,不断提高,投递尽量不要拖太后,后面很多没有hc,即使准备的好也没用了。
我前面投递实习的时候技术面其实不会特别难,不过也有例外,比如淘天的,还有腾讯AILab这种,不过多面还是有好处的,对于秋招面试也是积累经验的过程。
如果实在没有实习经历,也是可以把一些横向的项目加进去,包括校企合作,实践活动,这种有的也是算实习的。
实习看能不能转正,如果能转正就要好好准备,不能的话就趁早想想后路,实习的经历如何整理成体系,面试的时候问答到相关的问题如何回答,把工作点整理好,面试的时候就不慌。
除此之外,如果没有特别好的成果的话实习投递也有可能不容易找到,但是这也是一个打怪升级的过程,有实习还是远远大于没有实习的,没有大厂就先去小厂,后面有机会再去大厂,先找一个能去的。
秋招
如果有实习的话一般八九月就要回去准备秋招了,除非对自己非常自信能实习转正。对于有实习的有经历,但是秋招的准备会少一些时间,因为实习很多时候也挺忙的,个别实习好像能直接在公司刷力扣,不过这种极少,看部门和主管。没有实习的人秋招七八月的时候有比较完整的时间准备秋招的内容比如力扣八股,把项目好好复盘。
建议还是尽早投递,确实是越早越容易,所以早点开始准备秋招的时候就可以占有不少优势,前后期难度确实不同,基本上八月份面试的都容易进。然后整理一个表格,不同公司的啥时候开始投递,有些相关的群要关注下,有的学长学姐会进行整理,自己这个表格记录好公司、投递时间、岗位、base地,笔试面试情况和时间啥的,方便自己查看。
算法方向
对于算法方向,目前岗位很多是算法工程师或者AI工程师,这块需要的技能很多时候不是只限一个方面的,很多岗位问的时候是既有传统算法也有大模型,所以技能肯定是越多越好,绝大部分算法都不是研究型的算法,而是业务型的算法,这样的算法主要是以解决实际问题来的,无论传统算法还是深度学习或者大模型,根据实际问题选择,所以都会最好。当然也有不少是直接的大模型算法工程师,虽然这种岗问的时候也还是有一般的算法。具体来说,主要从以下几个方向展开。
视觉方向
这个方向也是前面做的人最多的方向,虽然很多人现在做的还是视觉的项目或者科研,但是确实不建议用这个来找工作,除非你能发CCF-C及以上的论文吧,虽然C也很勉强。现在视觉的岗位太少了,所以必须是做的比较深,有一定的研究才行,不然相关的算法都很成熟了,不太好用来找工作。
这个方向现在不适合单独作为一个方向找工作,但是也是算法工程师基本必不可少的一个基础,还是要会一些相关内容更好的。
以下是两个半可以做的方向,说是两个半是因为第三个方向部署推理这块的hc远远不如前面两个的。
大模型
这个方向是目前算法最好找工作的方向了,大语言模型和AIGC这块的需求很多。很多人都说自己没做过,可问题是22年11月底ChatGPT出来之前,有几个人是做大模型的?现在做大模型的人99.9%的都是大模型出来之后开始学的,这块的上手门槛没有那么高的。很多人准备一两个月做一个大致像样的项目,用来参加比如书生浦语浦源大模型挑战赛,或者阿里这种的大模型比赛,差不多获奖就可以拿来简历用了,只要被问到的时候能讲清楚就还是可以的。现在各行各业都在用大模型做一遍,仍然是个可以做的风口,虽然风口过去并不知道能做成啥样,但是这几年自己能赚到就可以了。
学习这个并不需要一上来直接看论文,看看相关的项目,和一些相对比较容易的开源课程,先上手了解整个体系,然后尝试做个玩具微调下,之后再去认真研究,是个比较好的学习方法。
搜广推
这个方向作为互联网的基础,有非常稳定的基础,但是对于应届生来说学校期间往往不做这块的内容,不过要是突击两个月还是可以做下的,不算特别热,但是hc还可以,互联网都招。
部署推理
这个方向涉及模型的量化、剪枝、蒸馏、推理、部署、推理框架、推理引擎,还要AI Infra这些,这些方向其实还是可以做的,尤其现在大模型落地对这块的需求还是不少的,即使不是大模型的部署,小模型的部署也是有需求的。不过这块就要深挖下了,很多时候涉及C++,难度就上来了,不过这块的hc数就远比不上前面了,而且相对不太好转方向,有的开的价还可以,有的不如算法,但是还是比开发高的,也算是一个可以尝试的方向。tensorrt、ncnn、tvm、onnnx,还有vllm、turbomind、triton这些都是可以学习的。
这个方向因为hc极少,只攻这一个方向还是不好找工作,但是问题在于,算法工程师的技能点之一是CPP和量化部署这块,包括AI研发岗,我秋招面的很多家都会问到这块学的如何,也问相关的细节,所以这块如果会一些也是有好处的。
面试内容总结
简历学习内容
大模型
实习相关
实验评价指标
- 正则匹配如何做的
- 类别非常不均的情况下
acc指标是否足够,不足使用了什么- 语义理解的评价指标
- 具体指标
- 为什么这样用
- 这一指标达到多少,什么意义
badcase有多少,是什么原因,如何处理的如何根据实验结果调整
prompt数据构造
- 数据量
- 构造方法
- 实际上下文长度是多少
- 数据截断是什么问题
数据如何标注的
- 真值从哪里来
- 标注的数据有什么问题
采用大模型而不是之前的机器学习方法的意义、优点
改进和上线所需措施
- 模型是否满足上线需要
- 如果不满足是因为什么,效果或速度还是其他
- 上线需要解决其他什么问题,后续需要做什么
相关理论
- 主流的大模型参数、量级、结构、最大上下文长度,如何选取
- Llama 系列
- 千问
- 盘古智子
- chatglm
- internlm
- 其他
- openai o1
- 大模型评测方法
- CoT 和实习中的应用
- 微调方法
- LoRA、QLoRA 等多种方法
- 多头 LoRA
- LoRA
- QLoRA
- 训练了哪些层
- 设置了哪些超参数,如
r、alpha等- 如何根据实际情况调整这些参数
- 分布式训练方法
- deepspeed
- zero
RAG 相关
- 原理
- 解决什么问题,为什么用 RAG
- RAG 的向量表征方法都有哪些,怎么做的
视觉
目标检测
- 模型
- YOLOv1~v11
- 各代演进和区别
- 总体发展理论
- DETR 等无
nms的模型- 模型架构
- 主干网络的变化和区别
- 金字塔融合方式的多种
- 中间模块和处理方法
- 图像增强
- 一般的几种
- mosaic 等多种方法
- 量化
- 量化方法
- 参数量
- 速度精度
- 剪枝
- 方法
- 对网络什么部分进行剪枝
- 参数量变化
- 速度变化
- CPP 部分主要包括哪些
- 具体这部分如何用的
人脸识别
- 人脸识别和检测部分
- 构建索引和检索理论
- 向量表征
- 相似度检索
- 活体识别
算法八股
理论
- Transformer 模型讲解
- LayerNorm 等多种
norm方式如 BatchNorm- Encoder 和 Decoder 相关
- RNN、LSTM、Transformer 变化
- 大模型中激活函数等多种常用的结构
- GQA
- MQA
- RMSNorm
- SwiGLU
- RoPE
- 激活函数
- ReLU
- Leaky ReLU
- GELU
- tanh
- sigmoid
- swish
- ELU
- 特征工程包括什么,如何做
- 常见的数据预处理方法有哪些
- 分布式数据处理原理(如 Hadoop)
- 计算机理论相关(如堆和栈的区别)
手撕
- Transformer
- 注意力
- LayerNorm
- KMeans
- NMS
- IOU 计算
最后补个学习的内容:算法工程师面试常考手撕题
引用链接https://mp.weixin.qq.com/s/TAFvUlqdyqP-W6C10F1Hzw
- 算法工程师面试常考手撕题
- 注意力(Attention)篇
- 手撕单头注意力机制(ScaledDotProductAttention)函数
- 手撕多头注意力(MultiHeadAttention)
- 手撕自注意力机制函数(SelfAttention)
- 基础机器学习算法篇
- 手撕 k-means 算法
- 手撕 Layer Normalization 算法
- 手撕 Batch Normalization 算法
- 解码算法篇
- 手撕 贪心搜索 (greedy search)
- 神经网络篇
- 手撕 卷积神经网络(CNN)法
- 手撕 二维卷积 算法
- 位置编码篇
- 手撕 绝对位置编码 算法
- 手撕 可学习位置编码 算法
- 手撕 相对位置编码 算法
- 手撕 rope 算法
- 面试题汇总
- 致谢
- 注意力(Attention)篇
注意力(Attention)篇
手撕单头注意力机制(ScaledDotProductAttention)函数
输入是query和 key-value,注意力机制首先计算query与每个key的关联性(compatibility),每个关联性作为每个value的权重(weight),各个权重与value的乘积相加得到输出。
1 | class ScaledDotProductAttention(nn.Module): |
手撕多头注意力(MultiHeadAttention)
1 | class MultiHeadAttention(nn.Module): |
手撕自注意力机制函数(SelfAttention)
Self-Attention。和Attention类似,他们都是一种注意力机制。不同的是Attention是source对target,输入的source和输出的target内容不同。例如英译中,输入英文,输出中文。而Self-Attention是source对source,是source内部元素之间或者target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。
1 | class SelfAttention(nn.Module): |
基础机器学习算法篇
手撕 k-means 算法
1 | import numpy as np |
手撕 Layer Normalization 算法
1 | import torch |
手撕 Batch Normalization 算法
1 | class MyBN: |
解码算法篇
手撕 贪心搜索 (greedy search)
贪心搜索(greedy search)在每个时间步 t 都选取当前概率分布中概率最大的词,即
直到 yt 为或达到预设最大长度时停止生成。
贪心搜索本质上是局部最优策略,但并不能保证最终结果一定是全局最优的。由于贪心搜索在解码的任意时刻只保留一条候选序列,所以在搜索效率上,贪心搜索的复杂度显著低于穷举搜索。
1 | def greedy_decoding(input_ids, max_tokens=300): |
手撕 Top-K Sampling算法
Top-K 采样(在每个时间步选择条件概率排名前 K 的词语,然后在这 K 个词语中进行随机采样。这种方法既能保持一定的生成质量,又能增加文本的多样性,并且可以通过限制候选词语的数量来控制生成文本的多样性。
这个过程使得生成的文本在保持一定的生成质量的同时,也具有一定的多样性,因为在候选词语中仍然存在一定的竞争性。
1 | def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0): |
神经网络篇
手撕 卷积神经网络(CNN)法
1 | import torch |
手撕 二维卷积 算法
1 | import numpy as np |
位置编码篇
手撕 绝对位置编码 算法
1 | class SinPositionEncoding(nn.Module): |
手撕 可学习位置编码 算法
1 | class TrainablePositionEncoding(nn.Module): |
手撕 相对位置编码 算法
1 | class RelativePosition(nn.Module): |
手撕 rope 算法
1 | import torch |
print(res.shape, att_scores.shape)面试题汇总
- 大模型微调的经验与感想分享
- 百度-NLP算法工程师面经
- 美团-大模型算法工程师面经
- 小米-NLP算法工程师面试题
- 好未来-NLP算法工程师面经
- 百度大模型算法工程师面经
- 昆仑天工大模型算法工程师
- 阿里大模型算法工程师一面
- 算法工程师面试常考手撕题
- 搜狐大模型算法工程师
- 字节大模型算法实习生
- 理想汽车大模型算法实习生
- 百度大模型算法实习生面试题
- 腾讯大模型算法实习生面试题
- 阿里大模型算法工程师一面
- 某大厂大模型算法工程师面试题
- 说说百度大模型算法工程师二面经历
- 阿里大模型算法工程师面试小结
致谢
- LLMs 千面郎君 更新版 https://mp.weixin.qq.com/s/C6NdO_Ebj3DQx2AVAAgQRQ
- LLMs九层妖塔 https://mp.weixin.qq.com/s/Eh0tY1zx2FqXQqIGa2dIBA
- NLP 面无不过 https://github.com/km1994/NLP-Interview-Notes
]]>来自: 算法工程师面试常考手撕题(更新)